Table of contents
- Introduction
- The Real Problem AI Products Face
- What is Fine-Tuning?
- What Fine-Tuning Does Not Solve
- What is Retrieval-Augmented Generation (RAG)?
- Why RAG Works Better for Real-World Products
- RAG vs Fine-Tuning: Side-by-Side Comparison
- When Fine-Tuning Is the Right Choice
- When RAG is the Better Choice
- When You Should Use Both (RAG + Fine-Tuning)
- Real Product Scenarios
- Performance, Cost, and Scaling Considerations
- Final Verdict
RAG vs Fine-Tuning: What Works Better in Real Products
Introduction
Modern AI solutions are increasingly based on advanced and powerful language models. However, many fail to produce accurate or reliable outputs when in production environments. In most cases, the model itself isn’t the issue, rather it is how external information and behaviour are specified or organised around the model.
As a consequence of these issues, two highly relevant but often misrepresented methods have been developed: fine-tuning and retrieval-augmented generation (RAG). As such, the two approaches are increasingly being incorporated into artificial intelligence training course pertaining to real; life systems and associated design activities, as opposed to simply model performance.
This article will discuss the numerous reasons that AI systems do not perform well once they are deployed; as well as detailing which method, specifically, performs well in an ongoing real-life deployment.
The Real Problems AI Products Face

Incorrect Responses and Hallucinations
Probabilistic patterns learned during the training phase determine how various LLMs would generate text. If they cannot access credible information, they will likely provide fluent but inaccurate responses. In a production environment, hallucinations reduce trust by users and create operational and legal risk.
LLMs Have Also Been Trained on Old Data
Pre-trained and fine-tuned models only work off of data that has been used in the initial training phase. Therefore, any new information, including updated policies, pricing, documents, and internal knowledge, will not be recognized unless the model is retrained.
Cost and Lag and Scaling Issues
There is great cost associated with training, creating, and maintaining custom models. With large prompts, repeated retraining, and redeploying models, costs become excessive and are very difficult to sustain as usage increases.
Why “Smart Models” Will Continue to Let Users Down
What is Fine-Tuning?
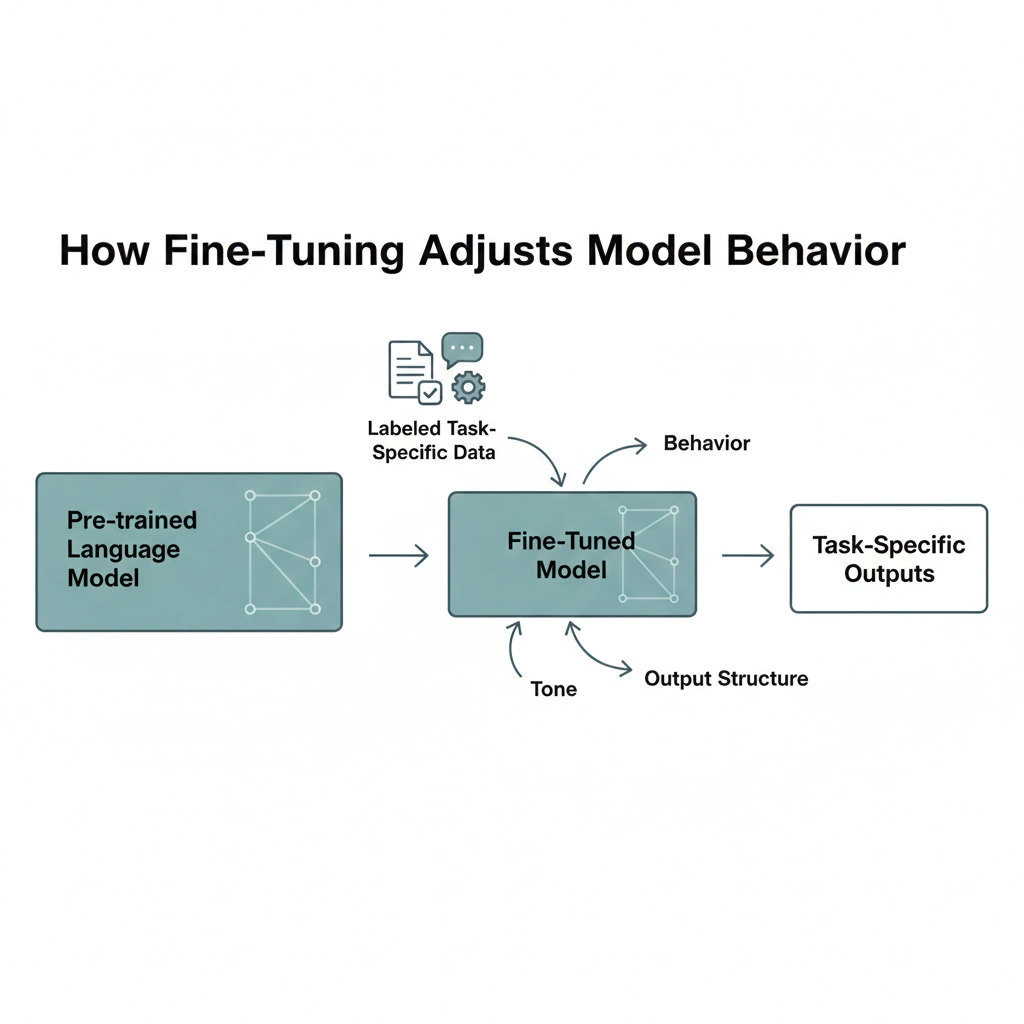
The Process of Fine-Tuning a Model
The fine-tuning of a model takes place by continuing to train the pre-trained language model (as opposed to training from scratch) on a dataset that is either domain and/or task specific. This allows the fine-tuning process to enable the model to adjust its internal parameters to be more aligned with the desired output(s).
Things Fine-Tuning Works Well For
Fine-tuning is beneficial for:
- Creating consistent tone/style across edits
- Improving accuracy for specific tasks
- Learning domain specific terminology
- Creating more structured or constrained outputs
Some Misunderstandings around Fine-Tuning
What Fine-Tuning Does Not Solve
Hallucinations Still Occur After Fine-Tuning
Fine-tuning does not prevent hallucinatory outputs from occurring, as the basis for any generative systems continues to produce analogous results. If there is a lack of available complete data—or if there are ambiguous data points—the chance exists for the model to generate incorrect information regardless of how well it was fine-tuned.
Restrictions On Data Currency
Retraining is the only acceptable means of changing the base, so fine-tuning cannot be utilized in an environment where data changes rapidly.
Costs of Maintenance / Re-Training
With each re-training cycle, the cost, performance evaluation, and deployment become a taxing operational burden.
Why Fine-Tuning Alone Cannot Work for Production
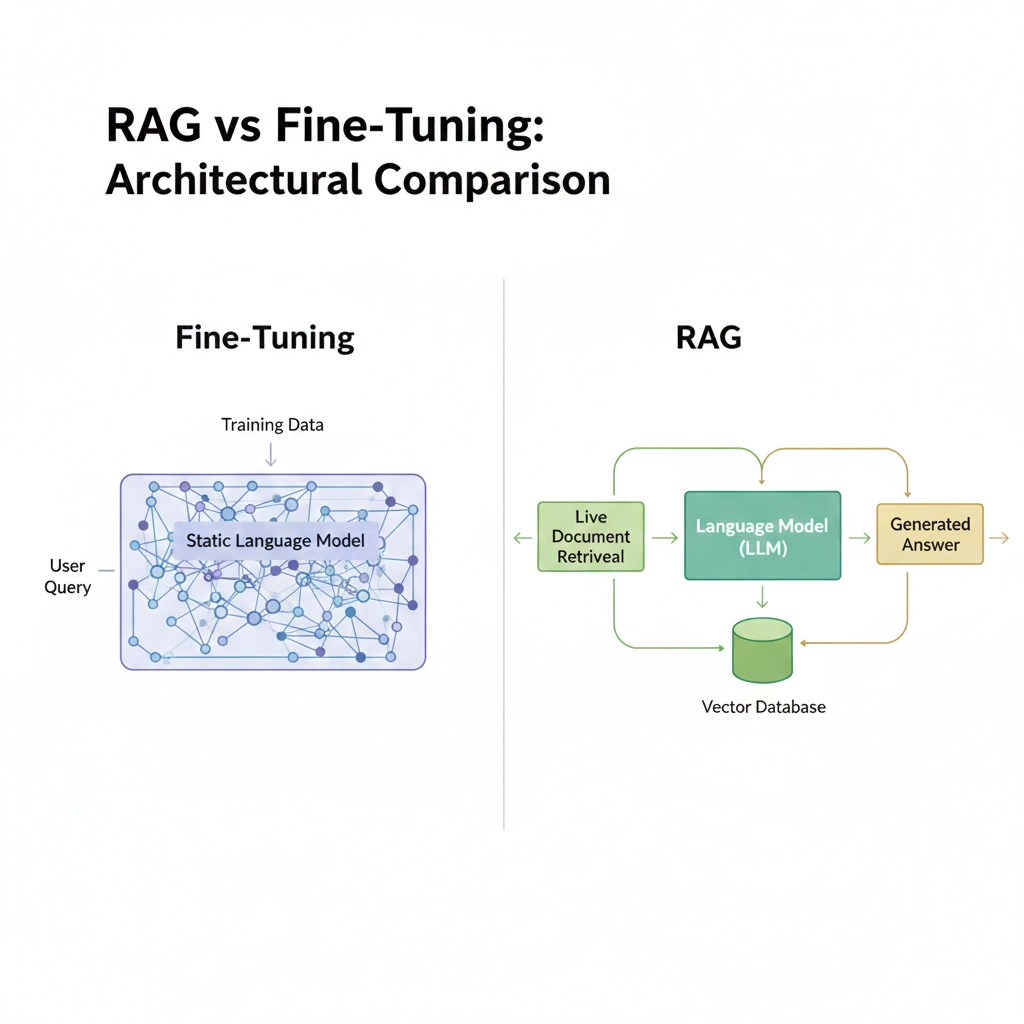
What Is Retrieval-Augmented Generation (RAG)?

How RAG Works Step by Step
RAG operates by retrieving relevant documents from an external knowledge base during inference time and incorporating them as context for the model to use when generating a response based on retrieved data.
Role of Embeddings and Retrieval
When an article is created, it is converted to a vector embedding and stored in a vector database. The semantic search identifies which content corresponds to each query.
Why RAG Changed Modern AI Architecture
Why RAG Works Better for Real-World Products

Minimizing Hallucinations
By grounding the response in returned data, you may avoid generating unsubstantiated or invented responses dramatically.
Using Current & Private Information
RAG tools enable you to access internal or external documents, databases, and new content without needing model weight adjustment.
Visibility & Traceability
RAG techniques make it easy to see what source documents were cited in generating a response, which is useful in auditing and compliance purposes.
Quicker Iteration; No Model Retraining Required
RAG vs Fine-Tuning: Side-by-Side Comparison
| Feature | Fine-Tuning | Retrieval-Augmented Generation (RAG) |
| Intended Use | Wrangling (adjusting) the model’s behavior, tone and performance for specific tasks | Returning external knowledge (current) to the model at the time of inference (when using the model to answer a question). |
| Knowledge Base | Has static knowledge (built into the model weights at training) | Has dynamic knowledge (retrieved from external documents or sources). |
| Managing Hallucinations | Does not reliably manage hallucinations | Significantly reduces hallucinations by providing sources for answers |
| Freshness of Knowledge | Needs to be retrained (to reflect fresh/new knowledge) | Has instantaneous freshness of knowledge on newly added/updated data. |
| Accuracy on Factual Queries | Has limitations beyond evolving/largescale knowledge base systems | High degree of accuracy on knowledge-rich and document- or source-based queries |
| Source Transparency and Traceability | Low degree of transparency/source traceability | High degree of transparency/source traceability (ability to show from which documents articles or citations were retrieved) |
| Cost over Time | High (due to retraining, evaluation and redeployment) | Lower (no retraining, only cost associated with updating the data and index) |
| Latency | Lower latency in inference | Potentially higher latency due to additional step taken during retrieval process |
| Scalability | Limited ability to scale (for data that changes frequently) | Excellent ability to scale (for large/rapidly growing data sets) |
| Data Security and Compliance | Higher difficulty to enforce and/or audit access to data | Lower difficulty to enforce and/or audit access to data. |
| Best Use for | Controlling style, structured output and specialization of tasks | Knowledge bases, corporate search, and internal tools. |
| Reliability in Production | Moderate degree of production reliability | High degree of production reliability |
When Fine-Tuning Is the Right Choice
Adjustments to characteristics, tone and behaviour
Fine-tuning your system allows you to create consistent behaviours in your language.
Customising language adaptation to domain-specific languages
By doing this, a model can be trained to understand specific terminology within particular industries like law or medical fields.
Structured output / consistency for every task
Fine-tuning can be used successfully for enforcing schemas or formats and providing predictable output for valid tasks.
Examples of how fine-tuning provides best benefit include:
- Text classification
- Sentiment analysis
- Output format
- Automated workflows
When RAG Is the Better Choice
Apps Requiring Lots of Knowledge to Operate
RAG will help to manage large or complicated collections of documents.
Data That Is Updated Regularly
RAG can provide updated information on a continuous basis with no additional training of users required.
Tools Used Within Companies
RAG is the backbone of search tools and internal knowledge assistants.
Use Cases That Require Government Regulations
RAG allows for the ability to track the source of documents and how they were used in a regulated environment.
When You Should Use Both (RAG + Fine-Tuning)

Description of the Hybrid Outlook
To control behaviour, fine-tuning, and for knowledge retrieval using RAG, both of which are used in similar motion as different forms of the same have been developed for application of production AI.
How Many Companies Combine RAG with Fine-Tuning?
A Lot of the time, companies will lightly fine-tune their models around tone and structure; however, when looking to retrieve information from RAG, they are more likely going to be using RAG for content accuracy.
General Architecture for Hybrid Systems
- Fine-Tuned Base Model
- Retrieval Pipeline
- Vector Database
- Monitoring and Evaluation Layer
Real Product Scenarios
Chatbots (for Ongoing Internal Knowledge Base Updates)
Through RAG you can provide accurate, timely responses from your internal documentation.
Customer Support System
Through RAG you can retrieve relevant policies; Fine-tuning will guarantee your”” responses maintain the same tone.
AI Search & Recommendation Tools
Through RAG you can perform a semantic search across countless databases.
Developer Tools / Co-pilots
Performance, Cost, and Scaling Considerations
Utilization of Tokens and Cost of Inference
RAG creates large prompts; does not require additional costs related to retraining.
Retrieval Latency Vs Model Latency
Efficient indexing and caching are critical to the success of RAG.
Maintaining Long Term Trade-offs
Final Verdict
RAG and fine-tuning perform complementary tasks that help solve different problems in an actual artificial intelligence product. Fine-tuning works best when determining how an AI will behave, including its tone, as well as providing consistent results when performing specific tasks; it cannot provide fresh or factual knowledge because it does not address those needs. The incorporation of RAG allows for generating responses from current, credible information, which is critical for any application that requires accuracy.
For the vast majority of production systems, but particularly for those that store large amounts of frequently changing data or for enterprises, RAG should serve as the foundational architecture upon which fine-tuning is applied selectively to improve the behaviour of the model. Using both approaches together offers a greater level of reliability, scalability, and sustainability over time, and is becoming the industry standard for successful deployments of AI.

