Table of contents
- Introduction
- What is Machine Learning?
- What is Supervised Learning?
- What is Unsupervised Learning?
- Key Differences Between Supervised and Unsupervised Learning
- Use Cases of Supervised Learning
- Use Cases of Unsupervised Learning
- Which Do You Use?
- What You'll Learn About These in an AI & Machine Learning Training Course
- Conclusion
Supervised vs Unsupervised Learning: Key Differences, Use Cases and How to Choose the Right ML Approach
Introduction
Machine Learning (ML) is no longer just a tech-term, it’s something we experience every day – often without realizing it. Whether it’s the spam filter in your Gmail inbox, or the suggestions you see on Netflix, or Amazon, machine learning is being applied behind the scenes. Simply put, machine learning is the science of programming a computer to make a decision based on data, with the knowledge that not every decision can be programmed.
If you are wondering how machines actually “learn”, and want to create some real-world projects, consider enrolling into an AI & Machine Learning Course. These types of courses take complicated topics and make them easier to understand, and provide opportunities for hands on learning with tools that makes machine learning less scary.
In this blog, we will cover two main types of machine learning, Supervised Learning, and Unsupervised Learning. At the end of this blog, you will know the difference, where they are used and how to decide which is best for solving your problem.
What is Machine Learning?
Definition and Concept
Essentially, Machine Learning is a data analysis technique that enables analytical modeling to be built automatically. Instead of being hard coded, there is no programming or explicit instructions needed, the ML system will learn from examples (in the form of data) and continuously improve the performance of the model.
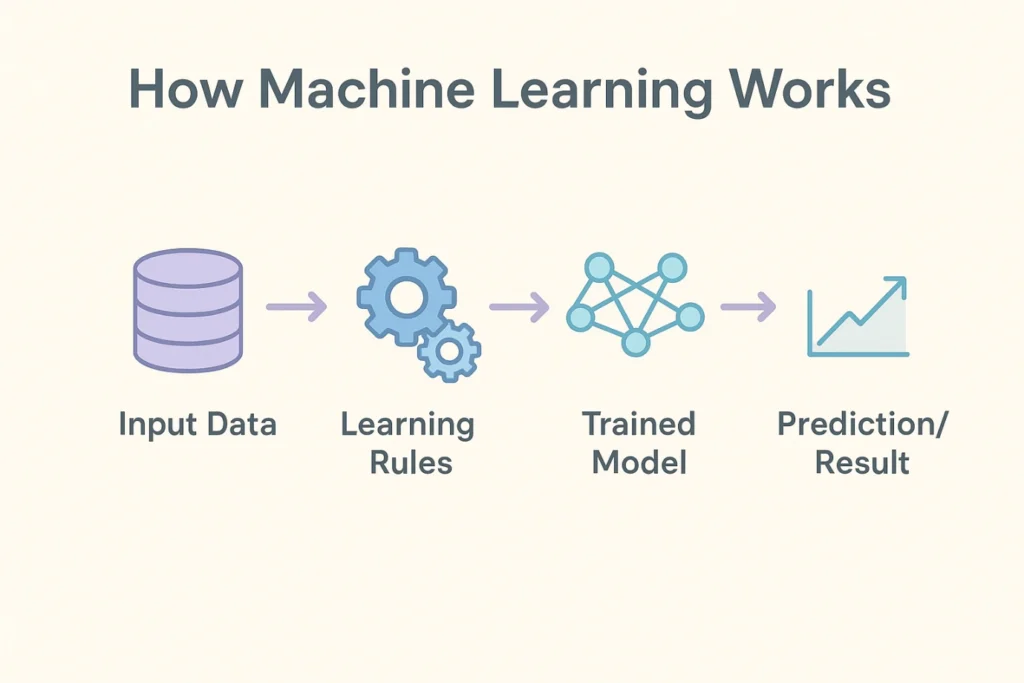
How Machine Learning Works (A Quick Summary)
Let’s say you wanted to teach a child how to differentiate between apples. You show them some pictures of apples (and some not-apples) and tell them which is which until they can begin to tell the difference. This is very similar to a machine learning process. You provide data to a computer system and the computer system then applies an algorithm that identifies the similarities and patterns in data in order to predict future outcomes, and/or group similar things in another data set together.
Types of Machine Learning
- Supervised Learning – The model is trained using labeled data (input and correct output)
- Unsupervised Learning – The model uses unlabeled data to discover hidden patterns.
- Optional Types – Semi-supervised Learning (hybrid of both types), and Reinforcement Learning (trial and error learning, often can be seen in robotics and gaming).
What is Supervised Learning?
Definition and Concept
Supervised learning is like learning with the answers. The user provides the computer with a vast number of examples with known input (measurements) and known answers (labels). The computer finds patterns in the data to allow it to provide the correct answer for new examples that it has not been trained on.
Key Features
- Need labeled data (you have to know the correct answer for all examples).
- The goal is to predict the right output for new inputs.
- You can measure how well the user has learned since you can compare their outputs to the known correct outputs.
Types
- Classification: The outcome is a category. Example: determining if an email is or is not spam.
- Regression: The outcome is a number. Example: predicting the temperature for tomorrow or overmorrow, predicting the price of a house.
How it learns (in everyday language)
Imagine you show the machine many images of houses, with the price for each image. The algorithm examines the features (size, number of bedrooms, location) and comes up with a rule linking those features to prices. Then later, when you show the machine another house, it uses the stuff in the rule to guess the price.
Popular Algorithms
- Linear Regression – Fits a straight line, and predicts numerical values.
- Logistic Regression – Predicts yes/no responses.
- Decision Trees – Flow chart which asks questions until you get an answer.
- Support vector machines (SVM) – Finds the best dividing bound between classes.
- Random Forest – A collection of decision trees vote together.
- k-Nearest Neighbors (k-NN) – Heart of the algorithm is based on finding the best example closest to the situation/existing case and using that or small group to determine a prediction.
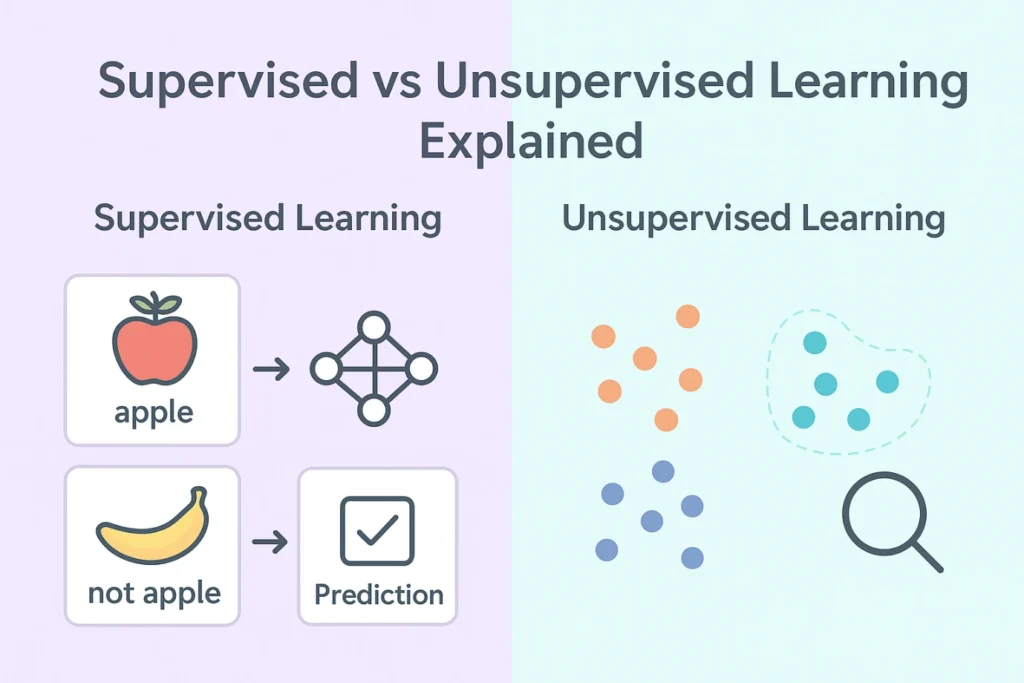
What is Unsupervised Learning?
Definition and Concept
Unsupervised Learning is like wandering without a map. Here, the data is unlabelled meaning the algorithm must try to categorize the data, find meaning or group similar things itself.
Key Characteristics
- Works with unusable data.
- Goal is to find hidden patterns, groups, or structure.
- Used mainly for exploration rather than prediction.
Types
- Clustering – Grouping similar observations. For example, identifying groups of customers who are similar in their behaviours.
- Dimensionality reduction – Discriminating unimportant data while keeping most of the important information. For example, compressing a high resolution image file.
Common Algorithms
- K-Means Clustering – Groups data into “k” groups.
- Hierarchical Clustering – Builds a cluster step by step like a tree.
- Principal Component Analysis (PCA) – Reduces the dimensionality of the data while keeping the most important information.
- t-SNE – Excellent for visualizing complex data in a 2D or 3D plot.
Key Differences Between Supervised and Unsupervised Learning

Comparison Table
| Aspect | Supervised Learning | Unsupervised Learning |
| Data Requirement | Uses labeled data (input + correct output) | Uses unlabeled data (only input, no answers given) |
| Goal / Output | Predicts outcomes or values for new data (classification or regression) | Finds patterns, groups, or structures hidden in data |
| Learning Process | Learns by comparing predictions with the known correct answers and improving over time | Learns by identifying similarities, differences, or structures in the data without any “right” answers |
| Examples of Use | Spam detection, disease diagnosis, stock price prediction | Customer segmentation, recommendation engines, anomaly detection |
| Complexity & Interpretability | Often easier to explain (especially linear models or decision trees) | Can be harder to interpret because clusters/patterns may not have obvious meaning |
| Evaluation Metrics | Accuracy, precision, recall, RMSE (we know the true answers, so we can directly measure) | Cluster cohesion, silhouette score (no true answers, so only indirect evaluation) |
Detailed Explanation
1. Data Requirement
Supervised learning requires labeled data. Example – email dataset where each email is labeled (“spam” or “not spam”).
Unsupervised learning does not require labeled data, it operates in raw data form, example – we can have purchase records and it will find the natural groups.
2. Goal / Output
Supervised learning seeks to predict an outcome or two – a category (spam/not spam) or numerical (house price).
Unsupervised learning does not predict. It discovers. It might uncover customers organize into three groups in respect of their buying habits.
3. Learning Process
Supervised models learn by looking how close their predictions are to a correct answer. The supervised model will adjust to find a better prediction.
Unsupervised models usually do not have a correct answer. They are will just try to organize the data, perhaps uncovering latent similarities or structure.
4. Use Cases
- Supervised: disease diagnosis, credit card fraud detection, tomorrow’s weather prediction.
- Unsupervised: grouping together similar news articles, recommending products/products, finding anomalous activity on a network, etc.
5. Complexity & Interpretability
Supervised models like linear regression or decision trees are often easily explained in layman’s terms. For unsupervised models, we can have a cluster or a reduced dimension that needs interpretation – understanding what it means is wonderfully enriching and is part of the analytical process.
6. Evaluation Metrics
Supervised models: easy to evaluate by measuring the accuracy or error rate since there is a true answer.
Unsupervised models: harder to evaluate since there aren’t labels; instead, we care about how well we generate the clusters, or the usefulness of the patterns.
Use Cases of Supervised Learning
Supervised learning is very effective for the situations when we know the outcome in the past, and want to predict the outcome for the future.
- Email Spam Detection – Supervised learning trains off of millions of past emails that were already labeled as spam/not spam. Over time, the model learns the words, links, and patterns that seem to be common among spam. Now, your inbox may already be cleaner!
- Fraud Detection in Banking – Historical data on fraudulent banking transactions could help a model identify unusual activity like suddenly purchasing high-value items or spending money in a foreign country.
- Disease Diagnosis in Healthcare – Historical patient data such as X-rays that are associated with a confirmed diagnosis is used to train models that are capable of generating potential for new patients. Conclusively, clinicians can use this step to direct decision making.
- Stock Price Prediction – Supervised models use prior financial data to predict potential future price movements (again, maybe not perfect since the market is complex), but at least can help aid in trend analysis.
- Customer Churn Prediction – Companies provide a model historical instances of customer activity and whether the customer left or stayed. The model can produce predictions of their current customers that are likely to churn before they actually churn, offering time to take action.
- Sentiment Analysis – Reviews labelled positive or negative, allow the model to analyze new reviews automatically. This means a company’s automatically know how customers feel about their products.

Use Cases of Unsupervised Learning
Unsupervised learning is useful when we don’t know what groups or patterns exist in our data, it allows for the revealing of hidden structures.
- Customer Segmentation for Marketing – Retailers do not treat all customers the same; instead they categorize groups of customers (as budget shoppers, loyal customers, occasional customers). This means they can provide each shopper with a personalized offer.
- Market Basket Analysis (Recommendation Engines) – Online retailers use algorithms to establish which products are most often bought together, bread and butter for example. This also impacts how stores recommend products which ultimately increases sales.
- Anomaly Detection in Network Security – Security systems learn what “normal” looks like. So if there is a large deviation from the norm (for example, 100 failed attempts to log in) this activity is flagged as potentially malicious behavior or anomaly regardless if the system has seen this specific activity before among all possible attacks.
- Document or Text Clustering – When documents or texts come in bulk, unlabeled algorithms can automatically cluster them. For example, suppose if you have a large bulk of news articles and apply clustering the algorithm may cluster it into articles from sports, politics, and technology by itself without providing it with labels or anything beforehand.
- Image Compression – Produces algorithms that identify and keep only what is important within images so it can effectively reduce the space taken on storage devices while keeping what is appropriate toward clarity.
Which Do You Use?
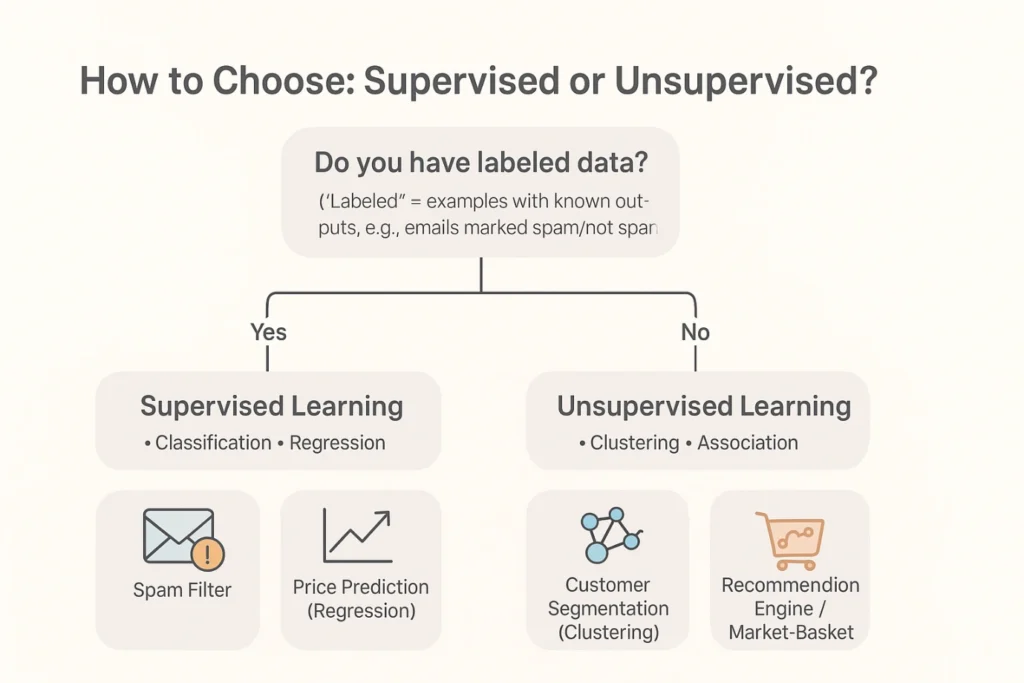
The answer to this question is dependent on your data and your aim.
- If you have labeled data and you want predictions → Use Supervised Learning.
For example: predicting if someone has diabetes using previous medical data then you would use supervised learning.
- If you have large amounts of data but without labels and want to find out what it reveals about the data → Use Unsupervised Learning.
For example: groupings of customers that behave similarly by only looking at the data, without someone putting labels on them beforehand.
Practical decision-making guide:
- Do you know the answer for previously collected historical data?
- Yes → Supervised (predict outcomes).
- No → Unsupervised (find patterns).
- Do you want prediction accuracy?
- Use Supervised.
- Do you want exploration and discovery?
- Use Unsupervised.
In many real-world business projects, organizations adopt a hybrid approach using both labelled and unlabelled data. They start with unsupervised learning to explore the data and develop categories, and then apply supervised learning to predict values in the resultant categories.”
What You'll Learn About These in an AI & Machine Learning Training Course
A good AI & Machine Learning Training Course like offered by Proleed Academy does not just teach you the theory behind ML, it delivers knowledge so you can learn practical application. Here is what you are typically going to learn:
- Data Preparation – Learn how to prepare raw datasets (clean errors, handle any missing values, format data in a certain way).
- Feature Engineering – Learn how to pick and create the input (features) so the models are more accurate.
- Supervised Learning Projects – You typically build projects to detect spam, predict prices or predict customer churn. These serve as a practical way for you to learn classification and regression.
- Unsupervised Learning Projects – You will typically be assigned projects to cluster customers, analyze text, and compress images. Again, these serve as your hands-on application to detect patterns.
- Model Evaluation – You will learn learn how to evaluate models to determine if they are successful (accuracy, precision, recall, RMSE, silhouette score).
- Tools and Libraries – You will learn how to use Scikit-learn, TensorFlow, Pytorch, and pandas – the tools that professionals use.
- Hands-on Practice – You will work step by step with real datasets using Jupyter Notebooks.
- Deployment Basics – You will learn how to take a trained model and actually deploy it and use it with an app or website.
- Best Practices – You will learn how to avoid overfitting, how to use correct training/testing splits, how to tune a model.
- Ethics of AI – You will learn about the importance of responsible AI and how to avoid biases.
This way, not only do you learn the concepts behind machine learning but you are also learning how to actually use them in practice.
Conclusion
Supervised Learning and Unsupervised Learning mark two significant approaches in Machine Learning. Supervised learning is about predicting outcomes using labeled data; unsupervised learning is concerned with identifying hidden factors using unknown labels, which are not known to the user. There are pros and cons to both methods, and both approaches are important to many applications we encounter in our daily lives, like spam filters and recommending products to customers.
There are many ways to begin your journey into machine learning; it is best to start with the foundational aspect of learning through a more structured course, working on small projects, and eventually moving to more complex and involved applications that strike your interest. Practicing with patience and practice rewards you; machine Learning becomes less buzzwords and more understanding for real-world problems in practical and meaningful ways.

